客服熱線:400-615-8698


銀行歷史數據集中系統的大數據技術實踐
?
來源:《金融電子化》雜志
?
目前Hadoop/HBase廣泛應用于各類具有大數據需求的企業,尤其是互聯網企業,實踐已證明其對大數據處理的適用性。銀行歷史數據系統具有的“大數據”特征,作者探索了采用Hadoop/HBase實現歷史數據集中系統。
?
目前銀行歷史數據系統主要采用關系型數據庫進行數據存儲,如Oracle RAC方式,但此方式具有諸多限定,例如數據量積壓到一定值后,將極大影響聯機查詢效率;只適合存儲結構化數據,難以滿足對半結構化和非結構化歷史數據的處理;成本較高,一套系統性能完善的歷史系統僅硬件成本將超過千萬。基于銀行歷史數據系統具有的“大數據”特征,我們探索采用當前廣泛應用的大數據技術解決方案,基于Hadoop/HBase的技術架構,給出技術結果、分析關鍵技術及技術特性。
一、Hadoop/HBase簡介
Hadoop是Apache軟件基金會的一個開源項目,目的是為用戶提供一個能夠對大量數據進行分布式處理的軟件框架,具有可靠、高效、可伸縮等特點。HBase則是APache的Hadoop的子項目,在Hadoop之上提供高可靠性、高性能、可伸縮的分布式數據庫系統。不同于一般的關系數據庫,利用HBase技術可在廉價PC服務器上搭建起大規模結構化數據庫集群系統。
HDFS是Hadoop分布式文件系統,為HBase提供了高可靠性的底層存儲支持。MaPReduce是Hadoop任務調度管理模塊,為HBase提供了高性能的計算能力。Zookeeper是Hadoop的分布式協調服務,為HBase提供了穩定服務和容錯機制。
此外,開源社區提供基于Hadoop的支持工具,如:Pig是一個基于Hadoop的大規模數據分析平臺,Hive是基于Hadoop的一個數據倉庫工具,使得在HBase上進行數據統計處理變得非常簡單。Sqoop則為HBase提供了方便的RDBMS數據導入功能,使得傳統數據庫數據向HBase中遷移變得非常方便。
Ambari是一種基于Web的、支持Apache Hadoop集群的供應、管理和監控的工具。Ambari目前已支持大多數Hadoop組件,包括HDFS、MapReduce、Hive、Pig、Hbase、Zookeeper、Sqoop等集中管理。
目前Hadoop/HBase廣泛應用于各類具有大數據需求的企業,尤其是互聯網企業,如Facebook、Twitter、ebay、雅虎、阿里、百度、華為、國內部分電信運營商等公司,國外摩根、花旗等銀行都已開展具體應用。其中,阿里、國內部分電信運營商都已經采用Hadoop/HBase實現對歷史數據(如話費單、購買交易記錄)的查詢等功能。阿里Hadoop/HBase集群節點數目將近5000個,實踐已證明其對大數據處理的適用性。
二、系統架構
基于Hadoop/HBase歷史數據集中系統邏輯結構如圖1所示。
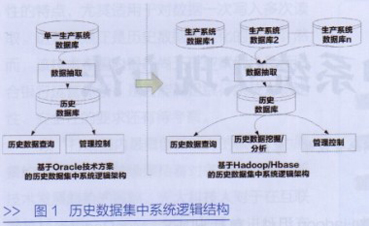
1.歷史數據獲取。歷史數據通過數據抽取系統,從相關生產數據庫中抽取所需數據,為不影響關鍵業務系統性能,可以通過災備線路將數據導入歷史數據庫中。相對于基于Oracle RAC的技術方案,新技術方案由于技術架構的橫向可擴展性,在不影響系統性能的條件下,可以同時對接多個生產數據庫,實現歷史數據的集中處理。
2.歷史數據查詢。歷史數據查詢模塊實現聯機交易查詢,根據查詢時間段,將查詢結果反饋給前臺用戶。相對于基于Oracle RAC的技術方案,新技術方案由于具備大數據量的處理能力,不但能夠提高查詢效率,而且歷史聯機查詢的時間范圍能隨著處理數據量擴展,例如從以前5年歷史查詢擴展到查詢30年的歷史數據。
3.歷史數據挖掘分析。相對于Oracle RAC的技術方案,新技術架構由于具有天然大數據技術特性,可以做到綜合多種生產數據來源,從海量歷史數據中進一步挖掘分析出所需信息,例如用戶行為分析等,以優化相關金融服務產品,提高用戶體驗、防范風險。
從圖2物理結構上看,相對于基于Oracle RAC的技術方案,新技術方案在展示層、應用服務層改動較小,在數據資源層改變較大,去除了磁盤陣列要求,數據全部存儲在HBase域服務器本地硬盤上。新技術方案中,數據存儲層,各服務器作用如下。
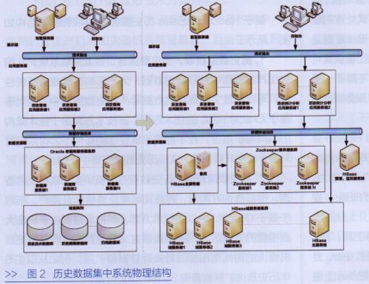
Zookeeper服務器集群:為HBase提供了穩定服務和容錯機制,為應用提供數據庫配置信息、命名、分布式協調服務。
HBase主服務器:實現HBase集群初始化,負責數據表格、域分配管理;負責管理域服務器的負載均衡,調整域分布。數據資源層只有一臺在線使用的HBase主服務器,但沒有單點問題,HBase中可以啟動多個HBase主服務,通過Zookeeper保證總有一個HBase主服務運行。
HBase域服務器集群:負責響應應用的數據I/O請求,向HDFS文件系統中讀寫數據,是HBase中最核心的模塊。所存儲的數據以文件形式保存在本地盤中。
HBase管理、監控服務器:基于Ambari工具,為運維人員提供HBase集群的管理和監控功能。
三、技術特性
采用Hadoop/HBase實現歷史數據集中系統,能夠滿足海量歷史數據高效的聯機查詢需求,并通過Hive/Pig等工具實現數據挖掘分析功能,具備如下技術特性。
高可靠性:Hadoop/HBase維護多個數據副本,確保能夠針對失敗的節點重新分布處理,其備份恢復機制以及計算任務監控機制保證了分布式處理的可靠性。高擴展性:Hadoop/HBase具備存儲和計算可擴展性,為處理海量數據,可以很方便地將集群擴展到數以干計節點規模,處理規模能夠達到PB級。高效性:Hadoop/HBase以并行的方式工作,處理速度高效。經濟性:基于Hadoop/HBase的大數據處理都運行在廉價的PC服務器上,無需購置昂貴的小/大型機以及磁盤陣列設備。
值得注意的是,新技術除具備以上技術優點外,其具體應用中也存在一定技術風險。首先,HBase不是傳統關系型數據庫管理系統,需要應用開發人員拋棄原有數據庫系統設計方法,重新掌握NoSQL等新技術知識。其次,Hadoop/HBase是全新的技術,目前國內精通此技術的人員較少,尚無專業技術服務支持公司,需要銀行自我培養人才隊伍。最后,Hadoop/HBase采用開源方式發行,相關自動化運維輔助工具較少,要維護管理好一個大規模Hadoop/HBase集群,需要投入一定數量的技術人員。

