客服熱線:400-615-8698


民生銀行:洞察數據規律啟迪銀行智慧
來源:金融電子化
民生銀行高端客戶流失風險預測研究項目從方法論、流程框架、理論模型、實證分析等方面入手,是綜合應用數據挖掘智能技術解決商業銀行客戶流失預測問題的一次全過程實踐。
大數據時代,全球經濟一體化及金融市場化促使國內商業銀行的經營管理模式發生了很大變化,各商業銀行紛紛將“以客戶為中心”的經營理念作為提高自身盈利能力和核心競爭力的重要基礎,并高度關注客戶關系管理與客戶數據挖掘。在客戶關系管理中,“老客戶的保留”是十分重要的研究領域。有研究表明,吸引新客戶要比保留老客戶的成本多5倍;向流失客戶銷售,每4人中會有1人成功,而向潛在客戶和目標客戶銷售,每16人中才有1人可能成功。已經發生流失的客戶尚有較高的挽回余地,若銀行能夠在客戶剛剛產生流失意向但還沒有真正流失時就準確識別出他們,并輔以適當的客戶關懷策略,這些客戶應具有更高的可能性被挽留,同時銀行和客戶雙方的利益都能得到保障,實現真正意義上的雙贏。
一、高端客戶流失風險預測研究項目簡介
1.項目背景。以打造“民營企業的銀行、小微企業的銀行、高端客戶的銀行”為戰略目標,民生銀行提出要實現自身的“二次騰飛”戰略轉型。同時,結合全行“十二五”信息科技發展規劃,民生銀行提出要發展數據挖掘智能信息應用,實現從“信息輔助業務”向“信息引領業務”的轉變。在銀行與客戶發生業務前或業務開展中準確探知“哪些客戶將要流失”、“哪些客戶將會違約”等預測信息,充分洞察隱藏在數據背后的業務規律,全面啟迪銀行智慧,與客戶攜手共贏。
作為戰略發展與經營管理的聚焦點、同時作為銀行業務與信息科技的協作點,“中國民生銀行基于數據挖掘技術的高端客戶流失風險預測研究”項目是近年來民生銀行信息化建設的重中之重。
2.項目概況。遵循“以客戶為中心”的經營理念,并基于全行已經完善成熟的企業級數據倉庫、數據集市等IT建設,全行高端客戶流失風險預測研究采用了國際先進的數據挖掘分類預測技術,并在此基礎上提出創新技術模型,為民生銀行零售業務高端客戶實現了客戶流失風險的自動預測;同時在銀行現有管理信息系統中部署了覆蓋全行的智能化高端客戶流失預警及客戶挽留機制,從而為由總行牽頭策劃、分支行具體實施的差異化高端客戶關系管理與維護提供精準信息。
民生銀行高端客戶流失風險預測研究項目從方法論、流程框架、理論模型、實證分析等方面入手,是綜合應用數據挖掘智能技術解決商業銀行客戶流失預測問題的一次全過程實踐,為民生銀行在此類問題上提出了一套完整的解決方案,包括構建客戶流失預測模型、產生潛在流失客戶名單以及針對潛在流失客戶制訂適當的挽留策略等,為銀行一線客戶營銷和客戶關系管理團隊提供“第一手”決策支持信息。經實踐,該研究成果具有預測準確性高、執行效率高等應用特點,能夠有效降低民生銀行零售高端客戶的流失率,實現了顯著的經濟效益。
二、數據挖掘方法論與課題研究思路
1.數據挖掘原理。數據挖掘是一套用以探索未知事物、獲取新知識的方法論。數據挖掘的核心思想是從存放在數據庫、數據倉庫、數據集市或其他結構性與非結構性數據/信息集的海量數據中,按照一定的模式,自動挖掘并萃取出一切存在的、有價值的、但人們用肉眼無法識別的信息和知識。確切地講,數據挖掘過程是一種決策支持過程,主要基于人工智能、機器學習、統計學、信息檢索、數據庫等技術,它高度自動化地分析業務生產中的數據和信息,做出歸納性的推理,從中挖掘出潛在的數據規律、規則、趨勢等,并加以有效應用,達到“總結過去、預知未來”的智能效果。
2.分類預測技術。分類預測是數據挖掘技術內容中的一項重要組成部分,它主要研究如何建立一個分類機制,將數據字段映射到某個給定的數據類標上。應用分類技術的目的就是要對未來一個未知類標的數據樣本進行類標預測,來識別甚至確定該樣本的類別歸屬。而在此之前,計算機需要對現存若干已知類標的數據樣本進行學習。
3.樣本學習方案。在全行現有零售高端客戶數據中提取一部分發生流失現象的客戶和一部分穩定客戶,通過搜集他們包括人口統計信息、產品簽約信息、金融資產信息、交易渠道信息、貸款信息在內的各類客戶特征屬性,構建一個客戶特征屬性與是否發生流失行為的映射關系。充分提煉“物以類聚、人以群分”的深層次含義,并以此預測客戶未來發生流失情況的可能性。
4.課題研究思路。課題研究首先要明確一個標準化、規范化的商業銀行數據挖掘流程框架,隨后結合相應的數據準備、字段篩選、模型選擇等問題,逐步思考:能否構建這樣一個映射關系實現客戶流失分類預測?能否結合業務需要實現客戶按流失可能性從高到低排序?能否從客戶特征中挖掘出客戶是否將發生流失的規律?能否對流失客戶進一步科學細分并挖掘細分類別規律,實現客戶挽留策略的個性化定制和資源的差異化配置?如何將分類預測模型及相關數據挖掘結果部署于全行現有管理信息系統中?
三、關鍵技術與主要創新
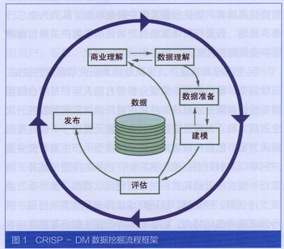
1.商業銀行數據挖掘流程框架。以“跨行業數據挖掘標準過程”(CRISP—DM)為藍本,首先確立了一套標準化、規范化的商業銀行數據挖掘項目實施流程框架(如圖1所示)。相比學術界公認的數據挖掘流程框架,CRISP-DM引入“業務理解”和“挖掘結果發布”步驟,并將“數據采集”、“數據融合”、“數據清洗”等步驟以“數據準備”加以概括,具備極佳的商業實用性。
2.商業銀行零售高端客戶流失定義。相比原本僅關注零售客戶儲蓄余額的下降來定義客戶流失,本項目引入客戶金融資產季日均額概念,即“儲蓄季日均額+理財季日均額+基金期末市值+國債期末市值+保險季日均額”。這一概念拓寬了銀行對零售客戶在綜合價值層面的考量,更加貼近銀行實際業務情況。經反復測算,為避免將客戶金融資產值的正常波動誤認為客戶流失,最終商業銀行零售高端客戶流失定義為:未來3個月客戶金融資產季日均額下降超過70%。
3.形成數據樣本準備策略。各家銀行在戰略發展、經營理念、市場定位等方面均存有差異,在客戶流失率方面自然也不盡相同。通常而言,國內商業銀行零售客戶的流失率每年在10%~40%水平。顯然,自然形成的零售客戶流失與非流失數據樣本并非類別平衡。針對數據挖掘分類問題,在考慮了存在類別不平衡現象的情況下,結合實證分析,給出了類別間樣本抽樣采用“1:1”配比的依據。
4.創新引入RFM模型進行字段派生。將“RFM(近期、頻率、金額)”模型引入商業銀行數據挖掘應用;結合高端客戶流失問題,將RFM概念加以延伸,創新提出了一套字段派生方法。傳統而言,建模往往采用客戶的“人口統計信息”、“產品簽約信息”、“金融資產信息”、“交易渠道信息”和“貸款信息”這五類以“靜態”為主的信息;基于RFM模型進而派生出客戶RFM相關“動態”為主的信息,能夠更加全面地描述銀行每名高端客戶。
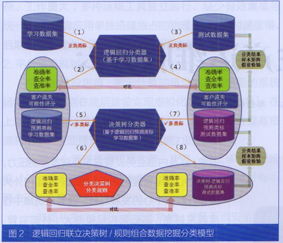
5.創新提出“組合數據挖掘”概念。傳統分類模型(如神經網絡、支持向量機、樸素貝葉斯等)僅能預測客戶是否將會流失,而無法將客戶按照(預測)流失可能性的從高到低進行排序。我國人口眾多,銀行零售客戶數量龐大,預測存在流失可能的客戶數量也是個不小的數字,為此銀行前臺客戶團隊需要知道哪些客戶更易流失,這將有助于客戶經理把握流失挽回工作的輕重緩急。此外,傳統分類模型無法向銀行提供客戶為何被預測為“將要流失”的原因依據,致使銀行在制定客戶挽留策略上無據可循、束手無策。在研究過程中,課題嘗試將邏輯回歸與決策樹/規則分類技術有效結合,創新提出了“組合數據挖掘”模型概念(如圖2所示),有效解決了上述問題。
6.從二類邁向多類,實現客戶科學細分。在“組合數據挖掘”研究結果的基礎上,針對銀行高端客戶挽留實踐中的實際問題,提出了以客戶流失分值(邏輯回歸分類預測結果)由高到低進行客戶排序,并按流失客戶的分布情況進行多類別細分,使原本二類分類問題轉化為多類分類問題(如圖2所示),為實現銀行客戶挽留的差異化資源配置提供了很好的依據。
7.先進的數據挖掘部署方案。將創新分類模型及相關數據挖掘結果部署于全行現有管理信息體系中,該部署方案簡化了原本繁瑣的數據挖掘預處理和后處理工作。在預處理層面,最大限度利用現有數據管理資源,在企業級數據倉庫基礎上部署客戶流失預警機制,省去了傳統數據挖掘建模中復雜繁瑣的數據集成和數據清洗等預處理工作,保證客戶數據的完整性和一致性。而在后處理層面,避免大量數據輸入/輸出資源占用,充分利用現有管理信息系統資源,實現數據挖掘智能預測結果的嵌入式部署,將客戶流失風險預測的“分析型”與“操作型”應用無縫對接。
四、結語與展望
隨著大數據時代的到來,商業銀行已經意識到推行“數據說話”、推動數據挖掘的迫切性和必要性。以銀行高端客戶流失風險預測研究為契機,民生銀行嘗試提出具有較高實用性的建模數據準備、字段篩選和模型應用部署方案;根據零售銀行實際業務需要,提出應用數據挖掘分類技術的模型選擇標準;通過選用成熟的邏輯回歸、決策樹/規則等數據挖掘分類技術,并加以有效技術整合、創新,形成了銀行高端客戶流失預測模型,可有效預測單一客戶的流失概率,支持對流失客戶進行科學細分,并展現客戶流失情況的預測依據,為銀行制訂差異化客戶流失挽留策略奠定基礎。此外,該研究成果對于商業銀行構建小微金融、信用卡、中小企業、事業部等其他類型客戶的流失風險預測模型,以及其他數據挖掘應用模型,如客戶信用風險評分、客戶營銷響應分析等,均具有重要借鑒意義。

